MLOps Zoomcamp 2023 Week 1: Intro
Blog about the week 1 homework

I have a passion for Python, Machine Learning and Azure. I love to share my knowledge and experiences through my writing. I strive to provide valuable insights and engage with my readers in a meaningful way. Thank you for visiting my blog and I hope you find something here that interests you. I believe in sharing knowledge and learning, building and practicing in public.
You can also watch the video of the implementation: MLOps Zoomcamp 2023: Week 1 Homework
Why I am doing this course?
I have some experience with Machine Learning Operations (MLOps) because I have operationalized some projects in my day job. I have done reading and hands implementation of Azure MLOps. The intention of doing this [MLOps Zoomcamp Course](https://github.com/DataTalksClub/mlops-zoomcamp) is to get a deeper understanding of the practices of MLOps.
What is the course about?
The course is intended to give a hands-on experience with several tools that are usually involved in operationalizing a Machine Learning (ML) application. I am going to customize the tech stack as we proceed. For example, instead of GitHub, I am going to make use of GitLab.
Prerequisite and Syllabus
The prerequisite for this course are:
Python
git
docker
comfortable with the command line
experience with machine learning
The syllabus can be found [here](https://github.com/DataTalksClub/mlops-zoomcamp#syllabus)
Week 1 Objectives
In week 1, the goal is to give an introduction to MLOps(What is it, why is it needed, MLOPs maturity model) and set up the machine learning development environment. As far as possible, I am going to work in the Windows Subsystem for Linux (WSL) setup unless I am required to use any of the cloud services. I have recorded a video on my [WSL setup](https://www.youtube.com/watch?v=IWfsbOzQgXA&list=PLM1WwwqnKtQtFxS_v7ZBf2mk-Xoiul54A). I launch VS Code and connect to my Ubuntu distribution within WSL. I create a new directory called mlops_zoomcamp_homwork that will contain all the notes and homework for the course.
I created a conda environment for the mlops zoomcamp course. These are the commands I used for creating the conda environment:
- conda create --name mlops_zoomcamp
- conda install pip
- conda install ipykernel
- python -m ipykernel install --user --name mlops_zoomcamp --display-name "mlops_kernel"
I have created 2 folders called data and notebook.
The
datafolder is used to store the dataset downloaded from [here](https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page). I use thewgetcommand to download theparquetfiles.The
notebookfolder will contain any of the jupyter notebooks that I make use of. I use the command. I will follow this naming convention format for the notebooksweek01-hw-eda.ipynb
Data
The data is about Yellow and Green Taxi trip records that have features about the trip start and stop time, pickup and dropoff location, fares, taxes etc.
We are required to download 2 Yellow Taxi datasets from the month of January and Feburary 2022.
The taxi data of the January month is used for training and the data of February is used as a validation dataset.
Problem Statement
The problem statement for ML here is to predict the duration of the taxi ride in minutes.
Note: The objective here is not to train the best model but a baseline.
Import data
After installing the required packages in the mlops_zoomcamp environment, I imported the datasets in the parquet format.
I inspected the data and
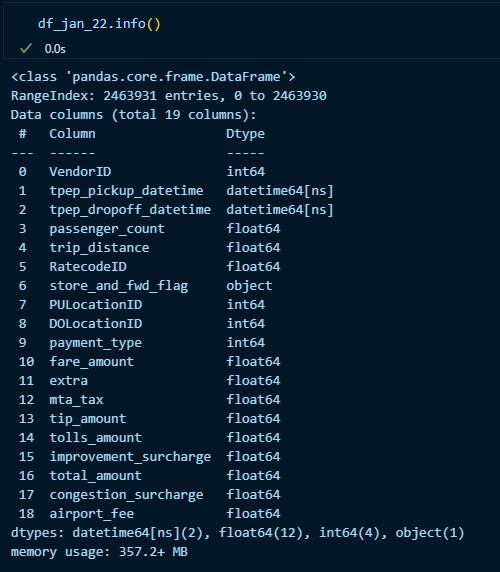
there are a couple of columns that are categorical in nature like the pickup and drop location id columns
the time of trip start and stop are in timestamp[ns]
some features do not add information for our problem statement like tax and fare columns
there is no duration column so we need to create it
I copied all the questions from the submission form first and followed the guidelines to proceed accordingly.
Question 1
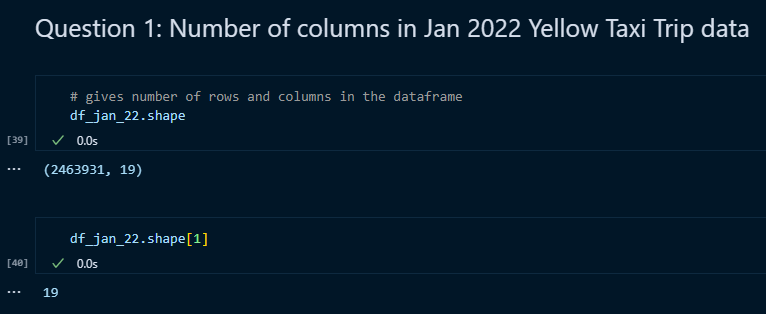
I used the shape method of pandas to get the number of rows and columns. 0 indicates rows and 1 is for columns.
Question 2
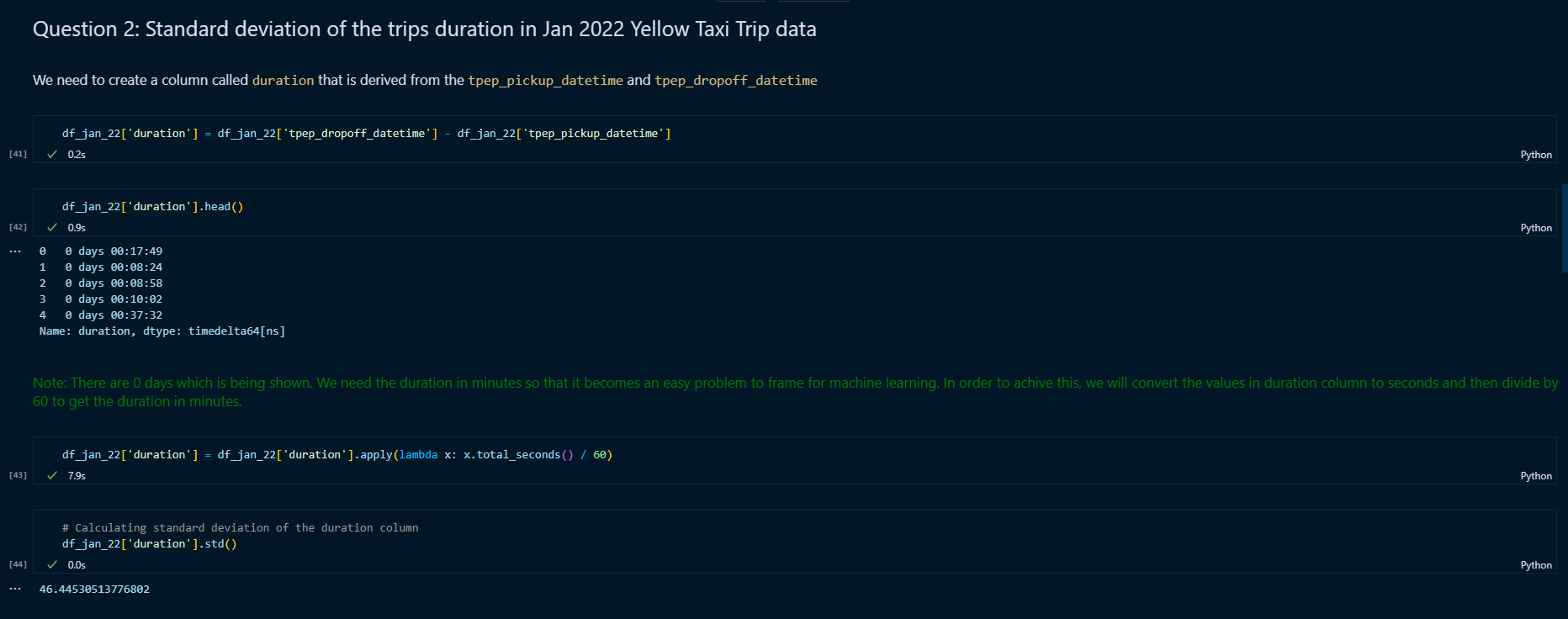
There were 2 steps involved here:
creating the duration column: this was done by subtracting dropoff time and pickup time. The duration column was converted into minutes by getting total seconds of each value in the column and then dividing by 60.
calculating the standard deviation: this was done by using pandas
stdmethod.
Question 3:
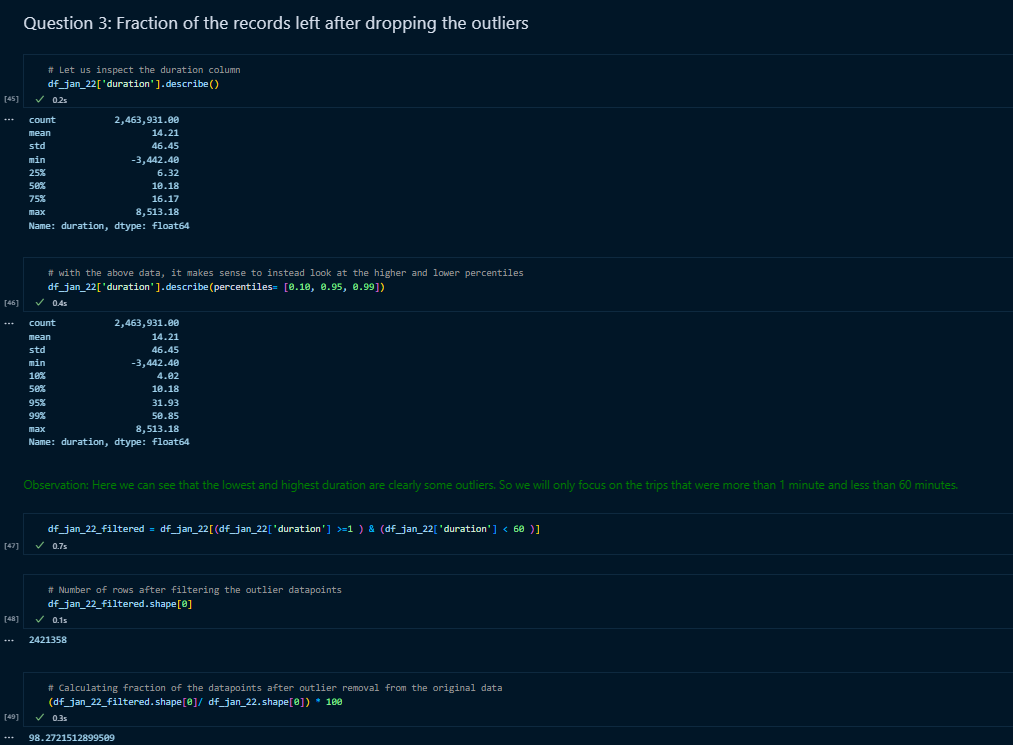
Here the duration column would indicate which rows were outliers. So using describe on the dataframe and looking at 10 and 99 percentile, it was evident that we can use trips greater than 1 minute and trips lesser than 60 minutes made sense. All other rows were outliers and didn't make it to the filtered dataframe.
The fraction was calculated by dividing this filtered dataframe free of outliers by the actual dataframe and multiplied by 100.
Question 4
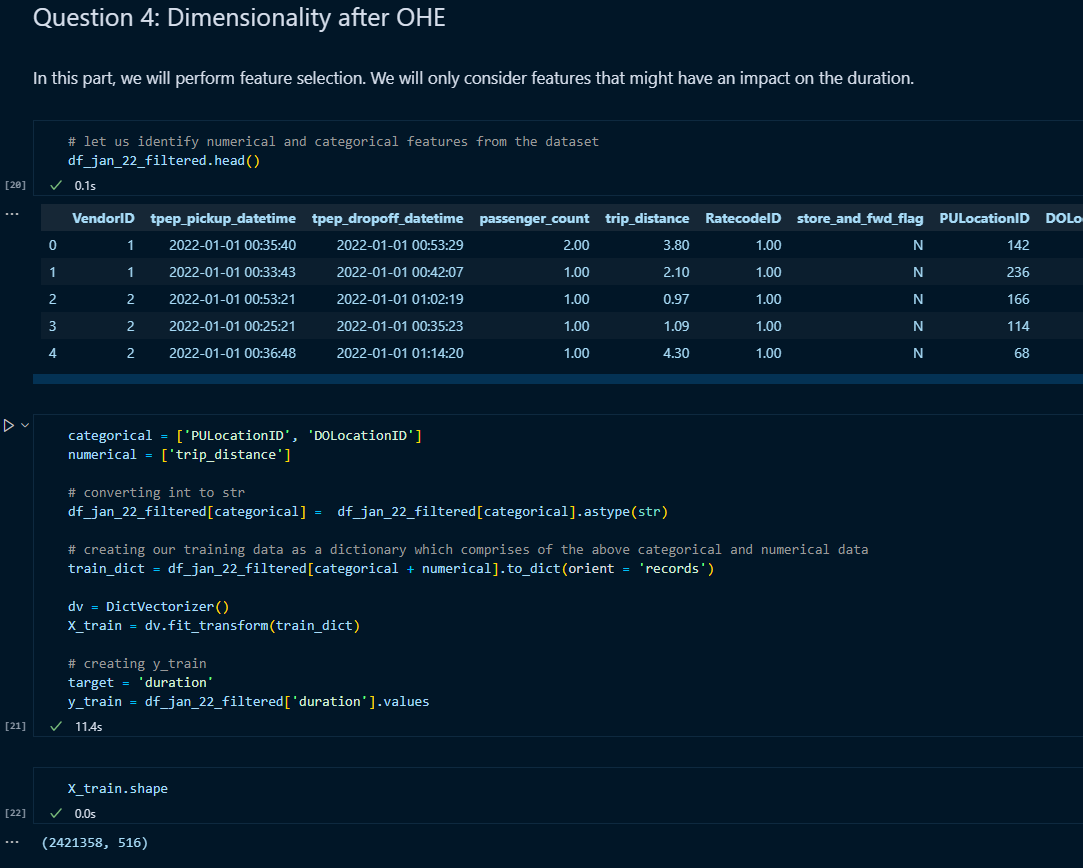
In this question, we were required to perform One Hot Encoding(OHE). But before doing it, we are required to pick categorical columns and convert str to int. Once the datatypes of these columns were changed, I also took into consideration the trip_duration for the baseline model. I created an object of DictVectorizer on this dataset and applied fit_transform. This is nothing but our training data X_train consisting of the above features. The duration values were stored in the y_trainvariable. Using shape, I calculated the dimensionality of the dataset.
Question 5:
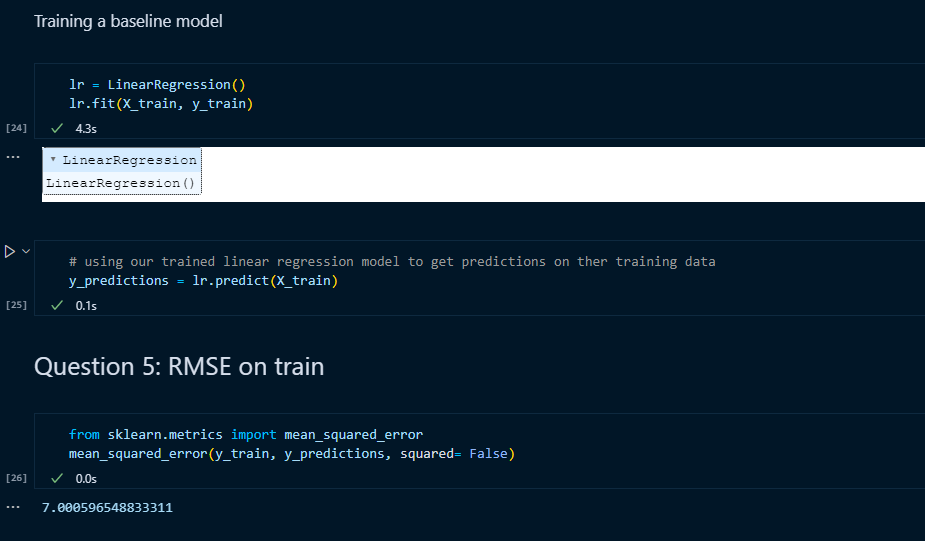
After training a baseline model of LinearRegression, the next step was to predict y values for the X_train dataset. To calculate the Root Mean Squared Error, we pass the y_train and y_predictions to the mean_squarred_error function from scikit-learn and set the squared parameter to False to get the RMSE.
Question 6

The last question also required the calculation of RMSE but this time on the validation dataset. The validation dataset was nothing but the dataset for the month of February. I did the same pre-processing on the validation dataset that I did on the training data and used the mean_squarred_error function again to get the RMSE.
Once the answers were generated from the code, its time to submit them in the homework submission link.
Some links that were referred to in this homework.
### Links
- Week 1: [Homework guidelines](https://github.com/DataTalksClub/mlops-zoomcamp/blob/main/cohorts/2023/01-intro/homework.md)
- Week 1: [Homework submission](https://docs.google.com/forms/d/e/1FAIpQLSfZRrhkwQv1LIHgItnc2-GnlcWTTeIV2QfJW2juxOIHkm83_Q/viewform)
- Data Source: https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page
- Data Dictionary: https://www.nyc.gov/assets/tlc/downloads/pdf/data_dictionary_trip_records_yellow.pdf
- 2023 MLops Zoomcamp Playlist Videos: https://www.youtube.com/playlist?list=PL3MmuxUbc_hKqamJqQ7Ew8HxptJYnXqQM
- Gitlab Repository: https://gitlab.com/saurabhkankriya/mlops-zoomcamp-2023



